Supercomputer 2019 Exhibits the Race to Exascale
Article By : Kevin Krewell

Lacking new top systems, the focus shifted to the next big systems for exascale computing. Intel, Nvidia, Arm, Cerebras and others made key announcements.
This year’s International Conference for High Performance Computing (SC19) — Supercomputer — conference in Denver didn’t make much news in terms of the Top500 supercomputer ranking. The top 23 positions remained unchanged from last year and many of the changes near the top had to do with systems that were retired. More new systems did come online with accelerators, including 42 new systems using Nvidia Tesla GPUs. Bucking that trend was a new champ of the Green500 list from Fujitsu, which factors in power and not just performance.

SC19 at the Denver Convention Center
(Source: SC Photography)
Lacking new top systems, there was still plenty of talk about the next big system for exascale computing (exceeding a quintillion, or 1018, calculations per second) scheduled to begin construction in 2021.
So far, the big winners for the next generation of U.S Department of Energy (DOE) exascale computers are AMD, Cray, and Intel. Cray, now a division of HP Enterprise, is the integrator for all three exascale designs and provides the slingshot interconnecting fabric. AMD is the winner of the Frontier system at Oak Ridge, providing both the CPUs and GPUs. Intel won the CPU and GPU design for the Aurora system to be built at Argonne National Laboratory. A third system has not yet been completely revealed, but Cray has been designated as the system builder.
So far, two key providers of components of previous systems (and the reigning champs on the Top500) — IBM and Nvidia — have been closed out on the exascale projects. One last system that has not been finalized is called El Capitan and represents the last chance for IBM and Nvidia to be part of the DOE exascale project. But even if they don’t win El Capitan, both companies have plenty of other opportunities in HPC.
Intel tries to steal the spotlight
Prior to, and during SC19, Intel held its own high performance computer (HPC) developer conference a few blocks from the Denver Convention Center where SC19 was being held. The highlight of the Intel event was a presentation by Raja Koduri, Intel’s senior vice president, chief architect, and general manager of Architecture, Graphics, and Software, in which he gave some early details of the GPU system designed for Aurora.
Both the Intel CPU and GPU will be built in Intel’s next-generation 7nm process, which has yet to go into manufacturing. This could prove to be a sticking point if Intel has any of the same problems that plagued its 10nm process node. The code name of the Intel Xeon CPU is Sapphire Rapids. The bigger reveal at the Intel event was the Intel Xe HPC GPU, which is code named Ponte Vecchio (named after the bridge in Florence, Italy).
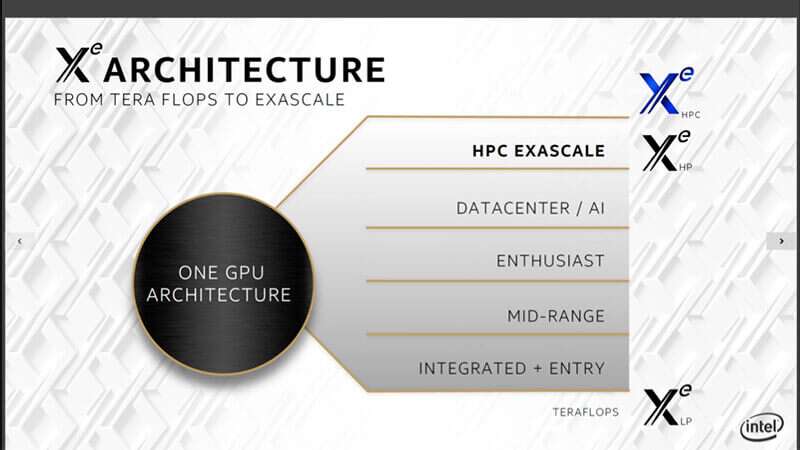
Intel GPU versions with Ponte Vecchio for HPC (Source: Intel)
The chips that make up the Ponte Vecchio GPUs are specially designed for HPC workloads with a combination of different vector computing tiles. While the primary goal of the HPC GPU will be crunching single and double precision floating point math, Intel will also support various popular AI data formats including INT8, BFloat16, and FP16.

Each Xe chip combines CPU and GPU compute modes (Source: Intel)
The system design will use additional Intel EMIB packaging technology to connect the GPU to high bandwidth memory (HBM). The Ponte Vecchio GPU will also incorporate Intel’s Foveros 3D chip stacking for a special memory interface chip, called the Xe Memory Fabric (XEMF), with a large cache, Intel called “Rambo.” With the large cache, Intel can improve the scalability to very large models.
Ponte Vecchio will be the pinnacle of Intel’s new GPU family, with a multichip module composed of eight chips per module and two modules per HPC GPUs. Intel will use its EMIB technology to connect the Xe compute elements to memories. The XEMF, with its Rambo cache will use Foveros 3D stacking technology. And Intel will have a new Xe bus that can coherently connect the Xe GPUs.

Intel Ponte Vecchio uses a special cache for HPC scaling (Source: Intel)
Intel is building a new software stack to tie all of its compute chips under one platform. The oneAPI platform for accelerated compute will cover CPUs, GPUs, and FPGAs. The initial release of oneAPI took place at SC19 with a beta release at version 0.5 with access available on the Intel DevCloud. Intel has a new programming language called Data Parallel C++ (DPC++) that starts with the Khronos’ SYCL language and then adds some Intel specified extensions. Intel will open source oneAPI and DPC++ and hopes that other chip companies adopt the platform.

Intel Ponte Vecchio module for HPC (Source: Intel)
At the heart of the Aurora supercomputer will be the compute sled composed of two Sapphire Rapids Xeons and six Intel Ponte Vecchio HPC GPUs. The GPUs will be interconnected by bus that is based on the recently announced CXL bus (which uses a PCIe 5.0 physical layer) called Xe bus and uses a new switch chip.
The Aurora project is a major challenge for Intel – the company is creating a new software stack, building a new GPU using a new semiconductor process and new packing technology. And it all has to come together in two years. It’s going to stress Intel’s capabilities in software, manufacturing and design.

Intel’s Raja Koduri with Rick Stevens, associate director of Argonne National Labs (Source: Tirias Research)
While Intel was releasing details of its platform for the Aurora exascale computer, AMD was also rolling out the software development platform for the Frontier exascale supercomputer. Frontier is an all AMD system with EPYC CPU and Radeon Instinct GPU. AMD already has a discrete GPU in production, while Intel developers have to make do with Intel gen 9 integrated graphic silicon for now. AMD’s open source answer to Nvidia’s CUDA is ROCM (and an alternative to oneAPI), which had its third major release. ROCM will now support Tensor Flow and PyTorch for ML workloads. But ROCM is the key software platform for Frontier developers and there’s significant funding in Frontier for ROCM development. AMD also touted an expanding ecosystem for its EPYC server processors at SC19.
Arm: It’s Good to be Green
A Fujitsu prototype system using its homegrown Arm processor, the A64fx, that proved performance and power efficient and topped the Green500 list. It was also one of the rare top performing supercomputers that did not utilize an accelerator such as a GPU or FPGA. The floating-point performance comes through the additions of the new scalable vector extensions (SVE) for the Arm cores that Fujitsu is the first to implement.

Fujitsu A64FX HPC processor. (Source: Tirias Research)
The other big news for Arm was that Nvidia will release a reference machine learning system using an Arm-based Marvell ThunderX2 server board. Nvidia will provide full-stack CUDA library support for the whole Arm ecosystem. Speaking of CUDA, while Intel’s oneAPI is in beta at version 0.5 and AMD’s ROCM is at version 3, Nvidia’s CUDA is at version 10.2. Nvidia’s challengers still have a way to go to match the robustness and maturity of its CUDA ecosystem. This article outines Nvidia’s delivery on its promise to support Arm.
Microsoft made a number of partner announcements for Azure. With Nvidia, its offering an instance that Nvidia likes to call “Supercomputer on demand.” The Azure cloud will have 800 Nvidia V100 GPUs in its datacenter connected by Mellanox switches. It will be possible to set up a container for an HPC application. Microsoft is positioning its Azure cloud as a platform for new technologies.
Before SC19, Graphcore and Microsoft announced that the Graphcore systems were now available on Azure cloud, which was a big win for Graphcore, which had been quiet recently.
AI startups show up in force
While there are similarities between systems designed to run HPC workloads and those used for AI training, there are distinct differences as well. Which is why dedicated AI training chips are different from HPC chips. Nvidia’s V100 does combine both functions into one chip, but most of the AI startups have skipped adding the high-performance, double-precision, floating-point math usually associated with HPC systems. But scientists are finding uses for AI processing along with the HPC processors, which is why SC19 has become an important show for them.
Cerebras, the wafer scale AI startup, used the show to unveil its system, the CS-1. Previously, the company had shown its wafer-sized chip. With contracts already announced with Argonne National Labs and Lawrence Livermore National Laboratory, Cerebras has had interest from many other companies.

Cerebras CS-1 at SC19. (Source: Tirias Research)
In addition to Cerebras, other AI startups made it to SC19. One panel included Cerebras, Graphcore, Groq, and SambaNova. SambaNova took this opportunity to show its first chip and reveal more details of its software-defined hardware approach to AI. The company’s reconfigurable dataflow unit (RDU) is built using a 7nm process and a collection of units that mix compute, memory, address generation, and coalescing results through a switch fabric. Groq describes its platform as software-defined hardware, with a mix of memory and compute units, that is capable of executing 1 PetaOp in one chip. Groq’s initial chip is made in 14nm process technology.
This year’s Supercomputing conference was a major event for Intel and the AI startups, but there was a lot of anticipation for the exascale systems coming in 2021. There is innovation happening in energy-efficient processing, with more Arm designs anticipated next year.