Do AI Chips Need Their Own DNN?
Article By : Junko Yoshida

DeepScale argues AI chips and sensor systems should come with DNNs optimized for the application. It will fundamentally change how companies buy AI technology.
For AI accelerators in the race to achieve optimum accuracy at minimum latency, especially in autonomous vehicles (AVs), teraflops have become the key element in many so-called brain chips. The contenders include Nvidia’s Xavier SoC, Mobileye’s EyeQ5, Tesla’s Full Self-Driving computer chip and NXP-Kalray chips.

In an exclusive interview with EE Times last week, Forrest Iandola, CEO of DeepScale, explained why this sort of brute-force processing approach is unsustainable, and said many of the assumptions common among AI hardware designers are outdated. As AI vendors gain more experience with more AI applications, it’s becoming evident to him that different applications are starting to require different technological approaches. If that’s true, the way that AI users buy AI technology is going to change, and vendors are going to have to respond.
Rapid advancements in neural architecture search (NAS), for example, can make the search for optimized deep neural networks (DNN) faster and much cheaper, Iandola argued. Instead of relying on bigger chips to process all AI tasks, he believes there is a way “to produce the lowest-latency, highest-accuracy DNN on a target task and a target computing platform.”
Iandola envisions a future when suppliers of AI chips or sensor systems (i.e. computer vision, radar or lidar) offer not just hardware, but also a faster, more efficient DNN of their own — a DNN architected for the application. In fact, it appears that any given vendor might need different DNNs for different compute platforms. If all of that is true, all bets in the AI race are off.
To be clear, neither chip companies nor sensor suppliers are posing this prospect today. Few even hint at the possibility of running a targeted AI task on a specific hardware.
Iandola and his teammates at DeepScale recently designed a family of DNN models called “SqueezeNAS.”
In a recent paper, they claim that SqueezeNAS “achieved substantially faster and more accurate models when searching for latency on the target platform.” The paper debunked a few assumptions previously made by the AI community about NAS, multiply-accumulate (MAC) operations, and ImageNet accuracy when applied on a target task.
DeepScale, co-founded in 2015 by Iandola and Prof. Kurt Keutzer, is a Mountain View, Calif., startup focused on developing “tiny DNNs.” The co-founders worked together at the University of California, Berkeley. DeepScale is widely respected in the scientific community for its research with fast and efficient DNN.
Manual designs
To appreciate the significance of recent advances in machine learning for computer vision, it helps to know the history.
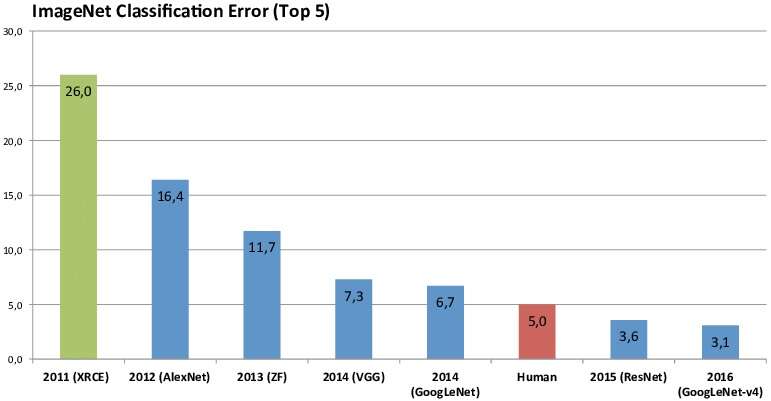
Remember when AlexNet won the ImageNet image-classification competition in 2012? This opened floodgates for researchers to concentrate on the ImageNet and compete by looking for DNNs that achieve the highest possible accuracy on computer vision tasks.
Typically, these computer vision researchers relied on expert engineers who hand-designed fast and highly accurate DNN architectures.
From 2012 to 2016 they improved computer vision accuracy, but did so by substantially increasing the resources needed to run their DNNs. Iandola explained that VGGNet, for example, won ImageNet in 2014, by using 10x more computations than AlexNet, and twice as many parameters as AlexNet.
By 2016, the research community had figured out that boosting accuracy by bloating the DNN’s resource requirements is “unsustainable.” Among the alternatives sought by researchers was SqueezeNet, which Iandola and his colleagues published in 2016 to demonstrate “reasonable accuracy” on ImageNet on tiny budget (under 5 megabytes) parameters.
SqueezeNet ushered in two significant variations. MobileNetV1 showed a way to dramatically reduce the quantity of multiply-accumulate operations (MACs) relative to SqueezeNet and other prior work. ShuffleNetV1 is a DNN optimized for low-latency on mobile CPUs.
Using ML to improve ML
As noted, all these advanced DNNs were developed by manually designing and tweaking neural network architecture. Because a manual process requires expert engineers and a lot of trial and error, this soon became a proposition too costly and time consuming.
So next came NAS, based on the idea of using machine learning to automate artificial neural network design. NAS is an algorithm that searches for the best neural network architecture.
NAS changed the AI landscape. Iandola told us, “By 2018, NAS had begun to build DNNs that run at lower-latency and produce higher accuracy than previous manually-designed DNNs.”
Reinforcement Learning
The computer vision community then started to use “reinforcement learning,” or RL — with the reinforcement based on machine learning (ML).
In other words, “ML gets feedback to improve ML,” explained Iandola. Under RN-based NAS, untrained RL gets proposals that specify the number of layers and parameters to train DNN architectures. Once the DNNs are trained, the results of training runs serve as feedback, which pushes RL to run more DNNs to train.
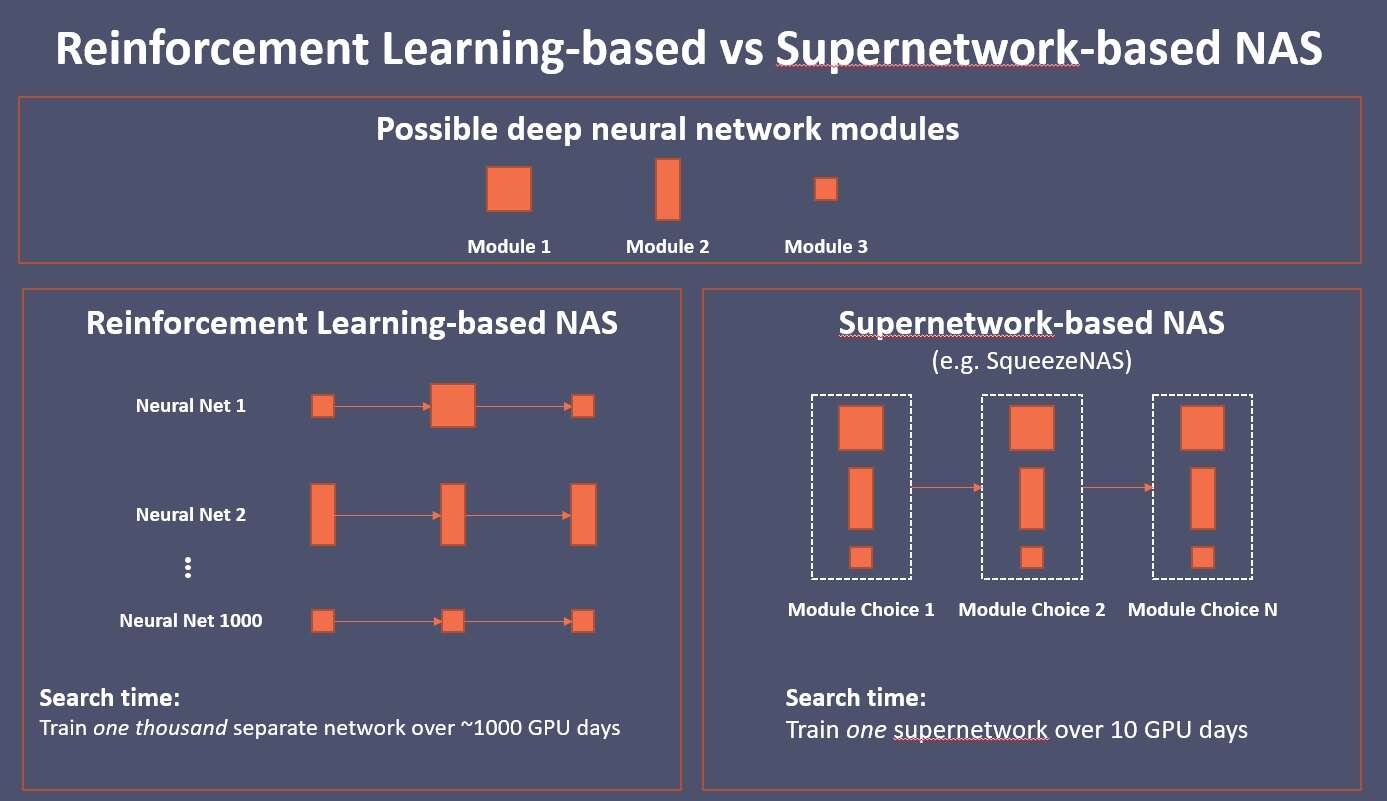
RL-based NAS proved effective. A good example is Google’s MnasNet, which outperformed ShuffleNet in both latency and accuracy on ImageNet. But it also had a key weakness: it costs too much. RL-based searches often require thousands of GPU days, training hundreds or thousands of different DNNs, to converge on the ideal design. “Google could afford it,” said Iandola, but most others could not.
Realistically speaking, an RL-based NAS trains a thousand DNNs, each typically requiring a GPU-day. Given today’s prices on Amazon Web Services, Iandola estimates that one search using RL-based NAS can bill out at $70,000 in cloud computing time.
Supernetwork
Against this backdrop, a new breed of NAS called “supernetwork”-based search emerged late last year. Its examples include FBNet (Facebook Berkeley Network) and SqueezNet.

“Instead of training a thousand separate DNNs,” Iandola explained, “supernetwork takes a one-shot approach.”
For example, a DNN has 20 modules and each has 13 choices. By picking a favorite choice for every module, “you are training one DNN that contains quadrillions of different DNN designs in one shot,” explained Iandola, “at the cost of about 10 DNN training runs.”
FBNet demonstrated that supernetwork based NAS can produce DNNs that outperform the latency and accuracy of MnasNet within ten GPU-days of search time. “That brings the search cost from over $70,000 to around $700 of AWS cloud GPU time,” said Iandola.
“10 GPU days” of search time is equivalent to “just over one day on an 8-GPU machine that you could fit in your closet,” Iandola explained.
Outdated assumptions
A brief history of ML shows us how the emergence of neural architecture search shifted the ground for computer vision research. But along the way, it also disproved some of the research community’s earlier assumptions, Iandola noted.
Which assumptions, then, need correction?
Most AI system designers assume that the most accurate neural network for ImageNet classification offer the most accurate backbone for the target task, noted Iandola. But computer vision consists of many AI tasks — ranging from object detection, segmentation and 3D space to object tracking, distance estimation and free space. “Not every task is created equal,” stressed Iandola.
ImageNet accuracy is only loosely correlated with accuracy on a target task. “It’s not a guarantee,” he said.
Take a look at SqueezeNet, created by Iandola’s team. It is a small neural network that achieves significantly lower ImageNet classification accuracy than VGG, but is more accurate than VGG when used “for the task of identifying similar patches in a set of images,” Iandola explained.
As classification tasks reach their limits, Iandola firmly believes it’s time to design different neural networks for different tasks.
Another prevalent assumption is that “fewer multiply-accumulate (MAC) operations will yield lower latency on a target computing platform.”
Recent studies, however, show that reducing MACs is only loosely correlated with reduced latency. “Neural networks with fewer MACs don’t always achieve lower latency,” noted Iandola.
Iandola maintains in his SqueezeNAS paper that it’s not just a different AI task that needs a different DNN. Choosing the right DNN for a target computing platform — such as a specific version of a CPU, GPU or TPU — will be important.
For example, he quotes FBNet authors who optimized networks for different smartphones. They found a DNN that ran fast on the iPhone X, but slow on the SamsungGalaxy S8. In the paper, Iandola’s team concluded, “Depending on the processor and the kernel implementations, different convolution dimensions run faster or slower, even when the number of MACs is held constant.”
Impact on autonomous driving
DeepScale today has in place several partnerships with automotive suppliers including Visteon, Hella Aglaia Mobile Vision GmbH and other unnamed companies. DeepScale has been developing tiny DNNs. The company claims they require less computing while achieving state-of-the-art performance.
Recommended
Visteon Works with DNN Vanguard DeepScale
In its SqueezNAS paper, Iandola and colleagues explained that the team used supernetwork-based NAS to design a DNN for semantic segmentation — such specific tasks as identifying the precise shape of the road, lanes, cars, and other objects. “We configured our NAS system to optimize for high-accuracy on the Cityscapes semantic segmentation dataset while achieving low-latency on a small automotive-grade computing platform.”
With the development of SqueezNAS, DeepScale positions itself to become a leading thinker on co-relations between optimized DNN, AI hardware, and specific AI tasks.
With AI chips about to flood the market, Iandola believes system designers must choose an accelerator wisely. They should consider exactly which AI task the hardware is supposed to perform and on what kind of neural network the hardware accelerator is designed to run.
Security cameras, autonomous vehicles and smartphones will all use AI chips. Given that the speed, accuracy, latency and apps required for each system are drastically different, identifying the right hardware and NAS becomes critical.
For OEMs to turn a testing AV into a commercial product, server blades currently stored in the AV’s trunk must come out of it, said Iandola. Carmakers could demand that hardware chip companies provide an optimized DNN that fits the hardware platform, he predicted.
For companies such as Nvidia, whose GPUs are backed by a large software ecosystem, this might not pose problems. Most other AI hardware suppliers, however, will be breaking out in a cold sweat.
Further, as a host of new sensors — cameras, lidars and radars — are get designed into AVs, car OEMs will face some harshg realities. For example, each sensor is likely to use different types of neural networks. For another example, lidars designed by different brands use different AI hardware. Iandola pointed out, “Today, neither sensor suppliers nor AI processor companies are offering their own recommended neural networks optimized for their hardware.”
It’s inevitable that tier one’s and car OEMs will start asking for optimized DNN matched to specific hardware and AI tasks, Iandola said. “We believe that using NAS to optimize for low latency on a target computing platform will continue to grow in importance.”
The cost of NAS is already dropping with the advent of supernetwork-based NAS. Hence, it might be time for hardware suppliers to start searching for optimized DNN of their own. Asked if DeepScale plans to fill the gap by either partnering, licensing or developing optimized DNN for AI hardware companies, Iandola said, “We haven’t really thought about that yet.”