NVMe Over Fabrics Set to Disrupt Storage Networking
Article By : Gary Hilson, EE Times

This year is already predicted to be a big one for NVMe-over-Fabric, and NVMe over TCP is expected to be a significant contributor.
TORONTO — This year is already predicted to be a big one for NVMe-over-Fabric, and NVMe over TCP is expected to be a significant contributor.
The NVMe/TCP Transport Binding specification was ratified in November and joins PCIe, RDMA, and Fiber Channel as an available transport. A key benefit of the NVMe/TCP is that it enables efficient end-to-end NVMe operations between NVMe-oF host(s) and NVMe-oF controller devices interconnected by any standard IP network. At the same time, it maintains the performance and latency characteristics that enable large-scale data centers to use their existing Ethernet infrastructure and network adapters. It’s also designed to layer over existing software-based TCP transport implementations while also ready for future hardware-accelerated implementations.
One of the most active participants in the development of the NVMe/TCP specification is Israeli startup Lightbits Labs, which is using it as a foundation for transforming hyperscale cloud-computing infrastructures from being reliant on a bunch of direct-attached SSDs to a remote low-latency pool of NVMe SSDs.
In a telephone interview with EE Times, founder and CEO Eran Kirzner said that the NVMe TCP enables simpler and more efficient scaling using standard servers while reducing costs by improving flash endurance.
While direct-attached architectures offer high performance and are easy to deploy at a small scale, Kirzner said, they are constrained by the ratio of compute to storage and lead to inefficient and low utilization of the flash. “Our customers are hyper-scalers," he said. "They’re trying to grow very rapidly, they’re adding more users, and more applications are running on top of their infrastructure, requiring more performance and more capacity.”
The Lightbits Cloud Architecture is disaggregated by taking advantage of the NVMe/TCP — it separates the CPU and the SSD to make it easier to scale, maintain, and upgrade while maximizing use of the flash, said Kam Eshghi, Lightbits vice president of strategy and business development.
“Different applications have different requirements for ratio of storage to compute. You end up with too much unused storage capacity, so you have stranded capacity,” Eshghi said.
A typical hyperscale environment designs for worst-case scenario, he said, by adding notes to increase performance or storage, but that leads to only 30% to 40% utilization of the SSDs. “As you get to a very high level of scale, this distributive model becomes complicated," he said.
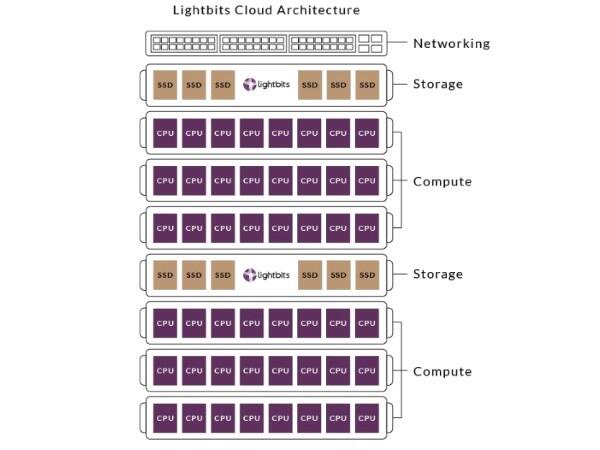
Lightbits uses the NVMe/TCP specification to disaggregate SSDs from CPUs to improve utilization of the flash and make hyperscale storage easier to scale.
Howard Marks, founder and chief scientist of DeepStorage, said that NVMe/TCP is a big story because RDMA is so fragmented. Choosing to run NVMe over RDMA requires committing to either RDMA over Converged Ethernet (RoCE) or its predecessor, Internet Wide-area RDMA Protocol (iWARP), as very few devices will handle both. RoCE requires converged Ethernet, he said, which means having to configure every port on every switch that faces every server or every storage device that’s going to do NVMe over RoCE.
“[Because] it’s called converged Ethernet, I’m probably going to want to configure all the features, and that means I need to get the network team involved," Marks said.
Meanwhile, iWARP has few requirements of the network and can be used in many different environments.
A big value proposition for TCP, said Marks, is that it’s well-understood, and although it does have some overreactions to congestion, a properly architected, small network shouldn’t have little to no congestion. But because TCP overreacts to congestion, it doesn’t fail; it just slows down. He said that NVMe over TCP is still substantially ahead of SCSI in terms of latency while still behind RDMA, which is likely to be the choice for high-performance computing. Enterprises are likely to start with Fiber Channel, but TCP will replace RDMA if the problem is addressing volume and scaling up, not specific, ultra-high-performance problems.
“NVMe over Fabric has many advantages beyond latency,” added Marks, including composability and higher performance by having greater parallelism. “You get more hops with the same latency, and that’s true regardless of what the transport is.”
For now, however, the fabrics market today is small. “We’re just barely at fabrics being ready for corporate use," Marks said. "There’s still a lot of management of the fabric pieces that are proprietary to each vendor you deal with. There’s still standardizing multi-pathing pieces that the committee has to do.”
This time next year, said Marks, it will likely break down with Fiber Channel taking 50% of the market, RDMA 30%, and TCP 20%. “Two years from now, TCP will be a much bigger slice,” he said.
— Gary Hilson is a general contributing editor with a focus on memory and flash technologies for EE Times.